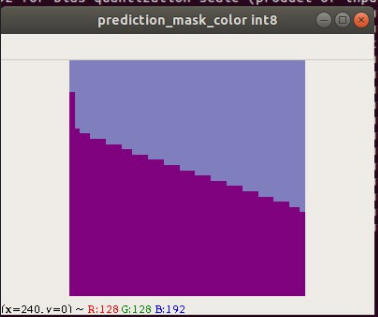
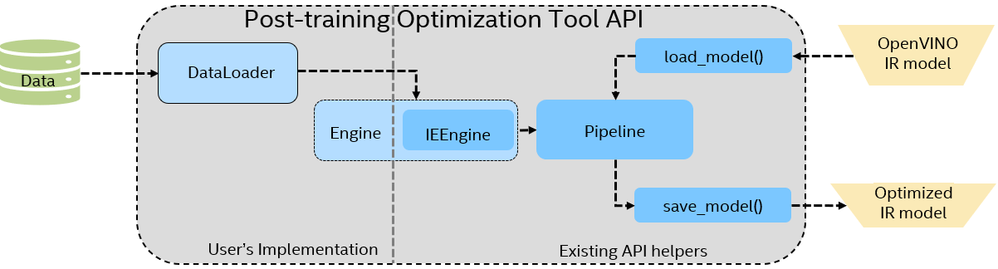
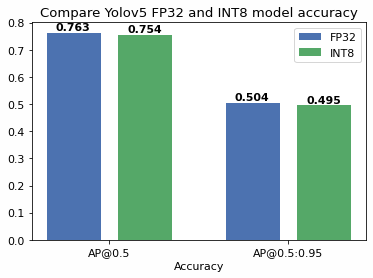
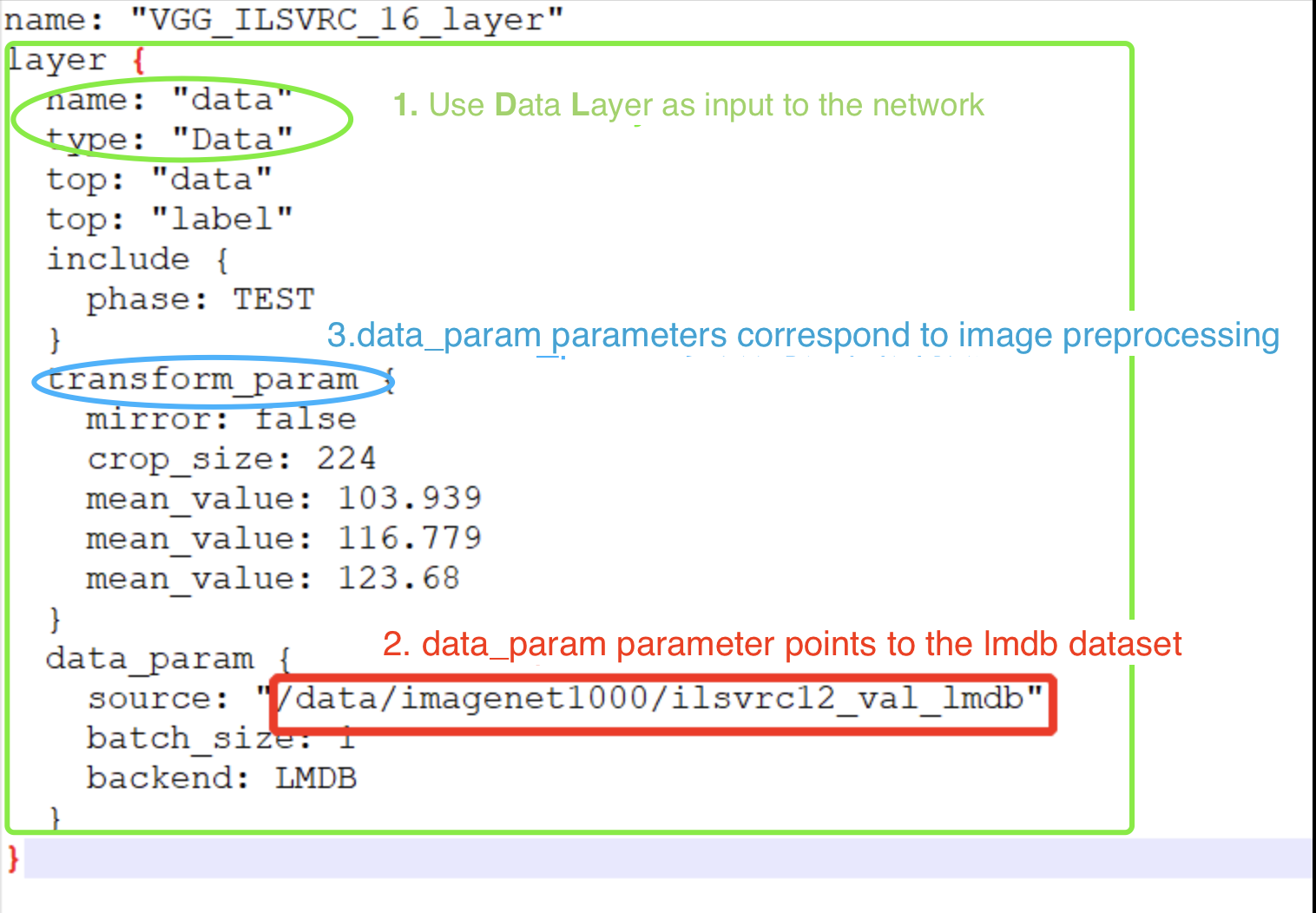
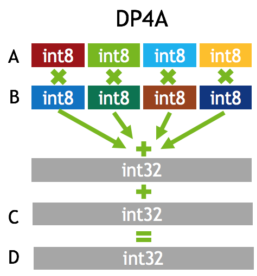
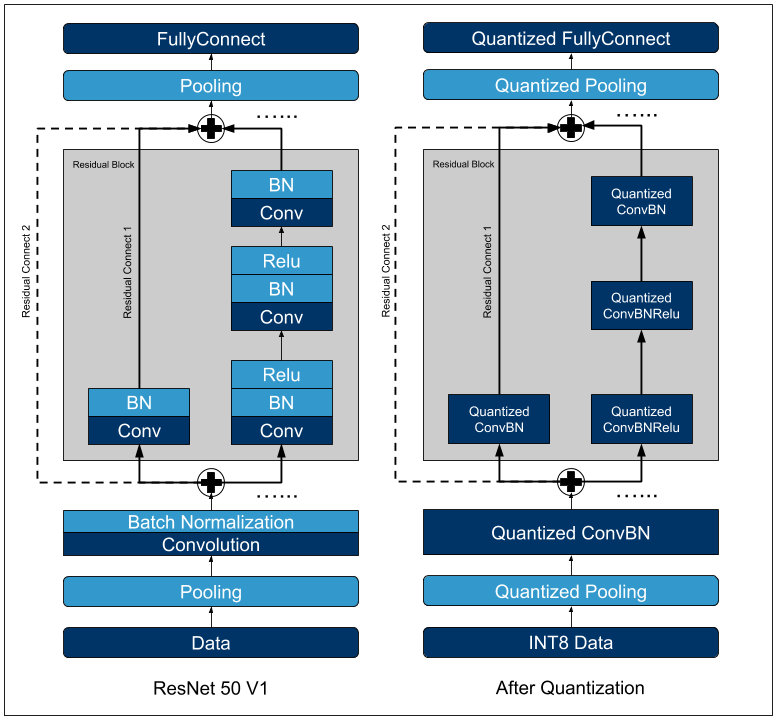
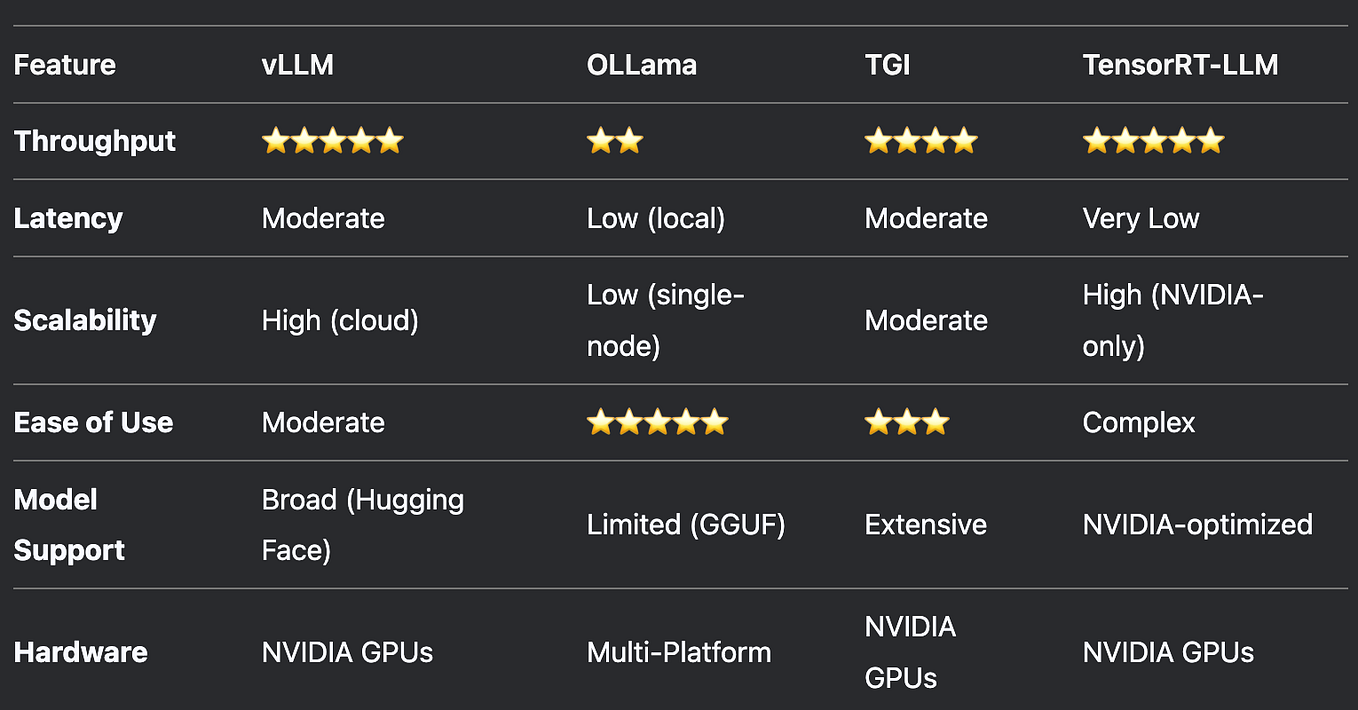
Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
Error while loading INT8 TFLite model · Issue #550 · ARM-software/armnn ...
Can not generate text correctly after loading an int8 model · Issue #80 ...
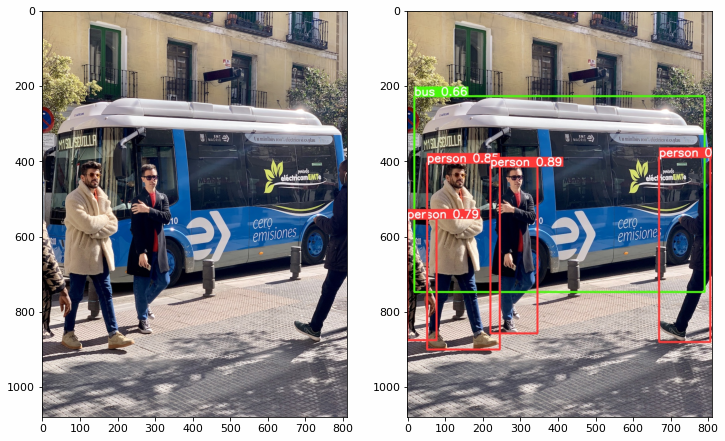
YOLOv5 Model INT8 Quantization based on OpenVINO™ 2022.1 POT API ...
Some predictions made by our int8 model | Download Scientific Diagram
lightx2v/Qwen-Image-2512-Lightning · How to use the int8 model
google/flan-t5-xl · int8 model consumes the same GPU memory as default ...
Manually load int8 weight from QAT model (quantized with pytorch ...
c++ inference int8 model error · Issue #16099 · openvinotoolkit ...
how to check precision of each layer after quantize to INT8 model ...
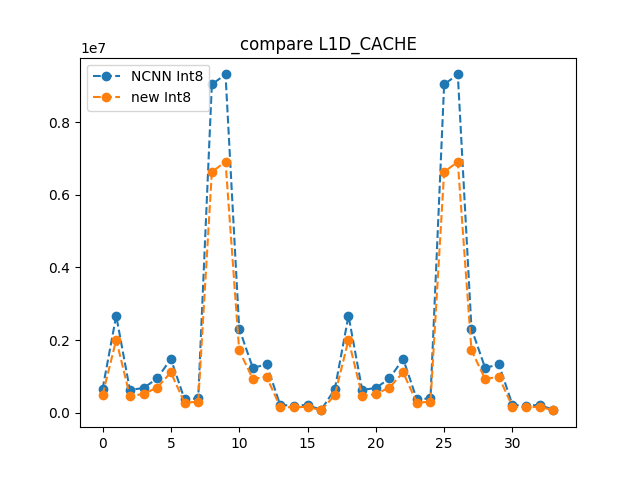
NCNN Int8 quantizated model load failed. · Issue #5279 · Tencent/ncnn ...
SegFormer Quantized Model (Int8) not loading weights properly. · Issue ...
int8 model quantization · Issue #521 · traveller59/spconv · GitHub
run int8 model reports · Issue #2832 · NVIDIA/TensorRT · GitHub
Int8 Quantized model same output on different inputs · Issue #23330 ...
How to Convert a Custom-Trained YOLO11 Model to a TensorRT INT8 Engine ...
The quantized INT8 onnx models fails to load with invalid model error ...
5.3. INT8 Model Generation — SophonSDKUserGuide v23.05.01 文档
Question about quantized INT8 model inference · Issue #2404 · NVIDIA ...
'q_config' is needed when export an INT8 model · Issue #1736 · intel ...
Onnxruntime fails on GPU loading inference with int8 models · Issue ...
INT8 engine for yolov8 model with imgsz=3040 · Issue #11502 ...
INT8 Calibration Reduces Accuracy of PyTorch MNIST Model on Jetson Orin ...
How to quantize a Language Model to int8 using optimum | by ...
microsoft/Phi-3.5-mini-instruct-onnx · DirectML INT4 and INT8 AWQ model ...
Unable to Run INT8 Engine for YOLOv8 Model · Issue #7 · marcoslucianops ...
FastRT INT8 model convert from weight to trt engine fails · Issue #592 ...
INT8 quantized model is very slow · Issue #6732 · microsoft/onnxruntime ...
exporting .pt model into int8 quantized .engine model · ultralytics ...
How to effectively quantize Yolov8 model to int8 ? · Issue #4097 ...
Converted fp16 or int8 model require up to 10 minutes to startup ...
Int8 model inference problem · Issue #528 · NVIDIA-AI-IOT/torch2trt ...
Quantized model INT8 is not able to do inference or convert to any ...
The model after INT8 quantization is slower than before and with higher ...
The weights of the int8 model do not match the qat model - quantization ...
INT8 Quantization of a custom model failed · Issue #4037 · NVIDIA ...
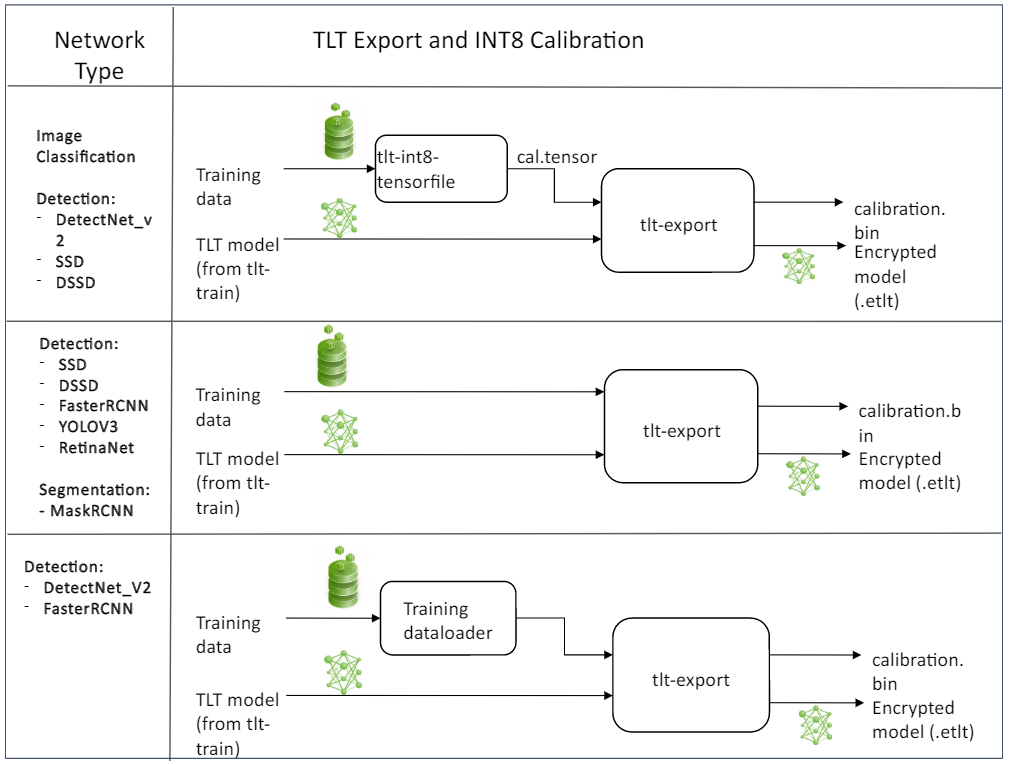
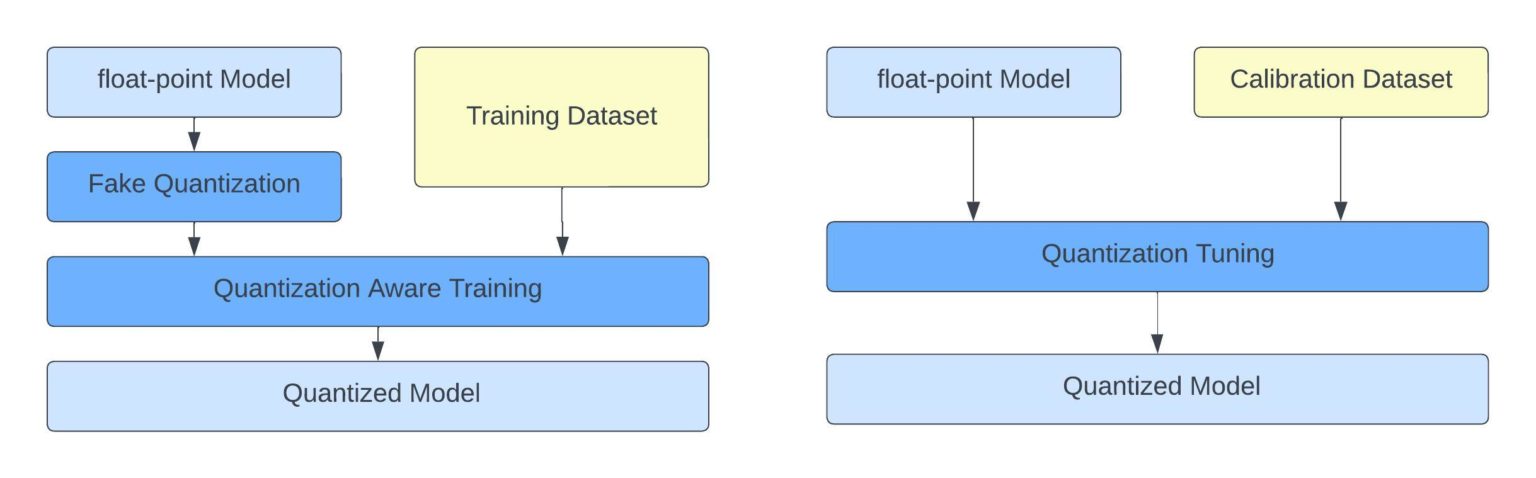
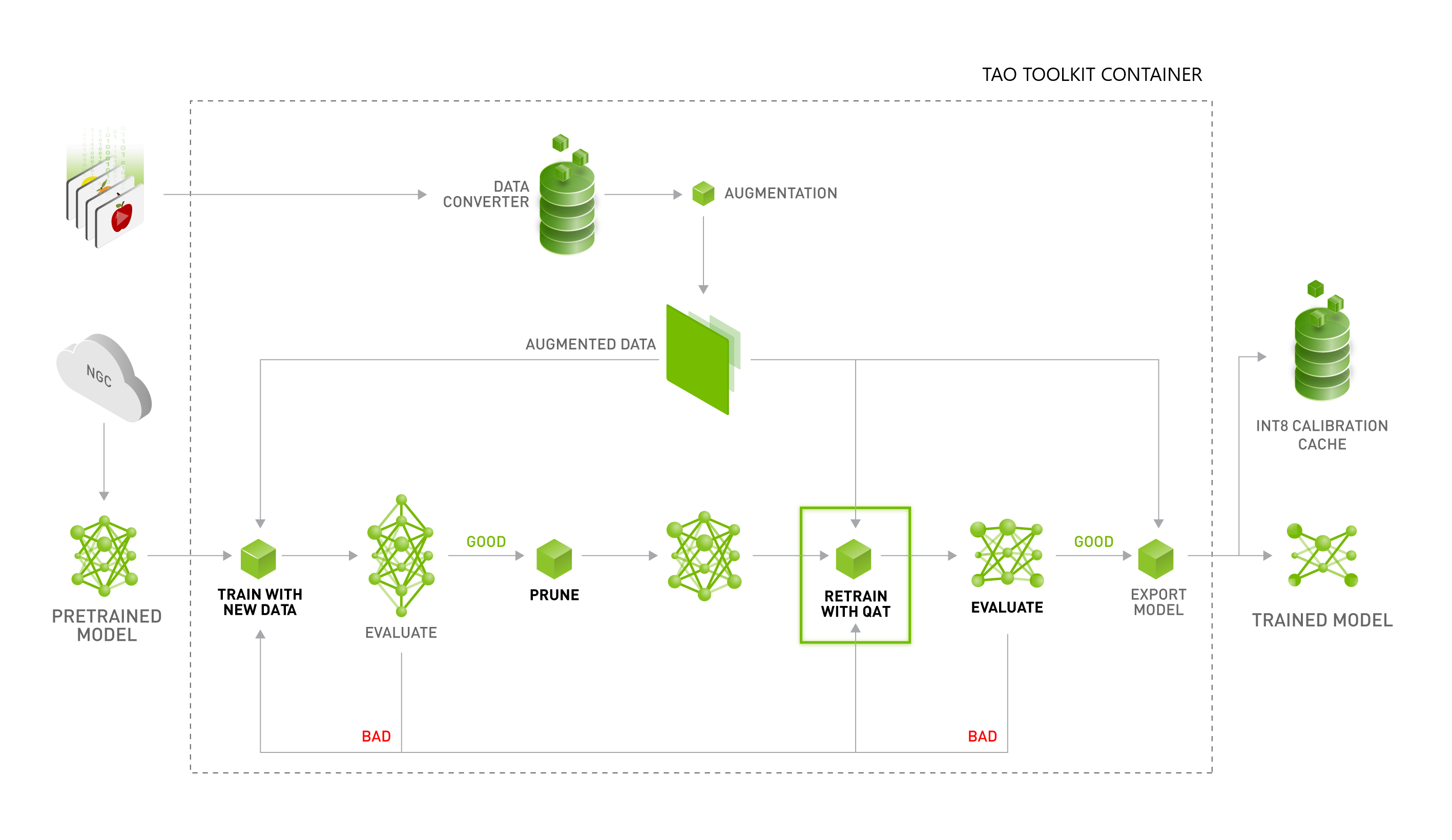
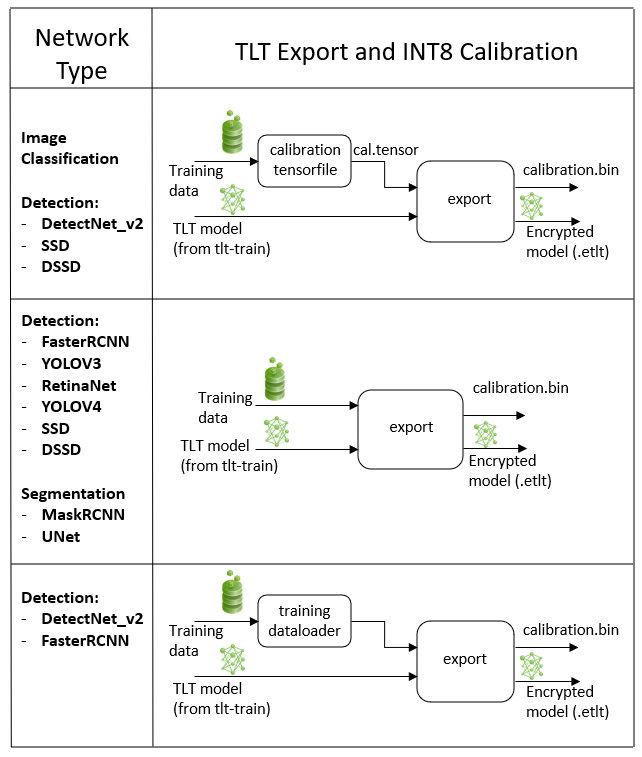
Exporting the Model — Transfer Learning Toolkit 2.0 documentation
Figure 1 from Performance Evaluation of INT8 Quantized Inference on ...
Model Memory Requirements Explained: How FP32, FP16, BF16, INT8, and ...
Local Large Language Models | Int8
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
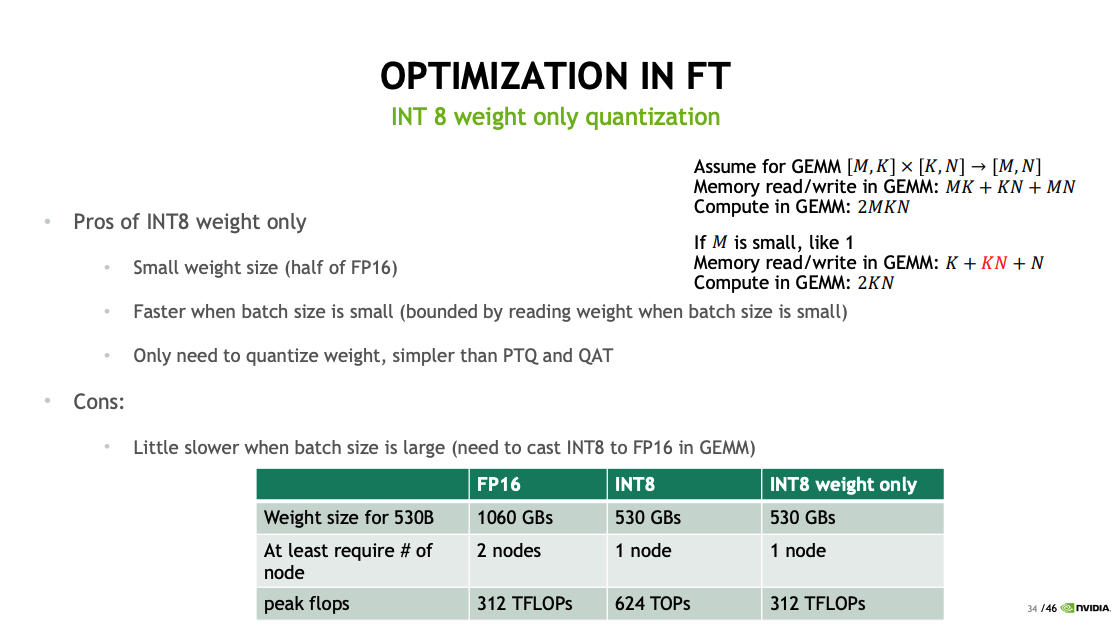
INT8 Support for GPT models · Issue #265 · NVIDIA/FasterTransformer ...
Quark Quantized INT8 Models - a amd Collection
how to build an int8 model? · Issue #3895 · onnx/onnx · GitHub
What Is int8 Quantization and Why Is It Popular for Deep Neural ...
questuion : how to inference Int8 models (GPT) supported through ...
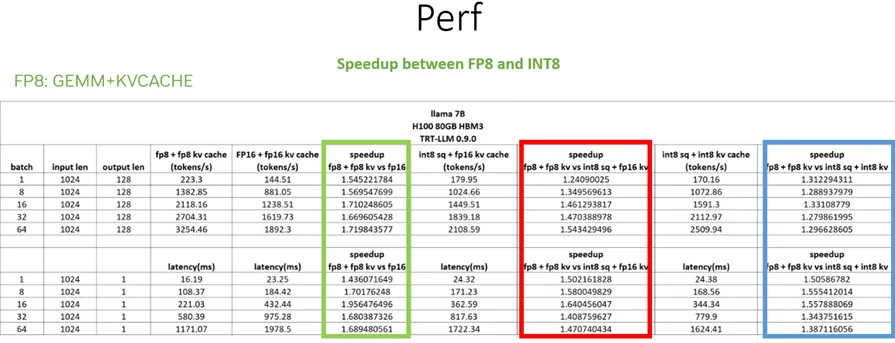
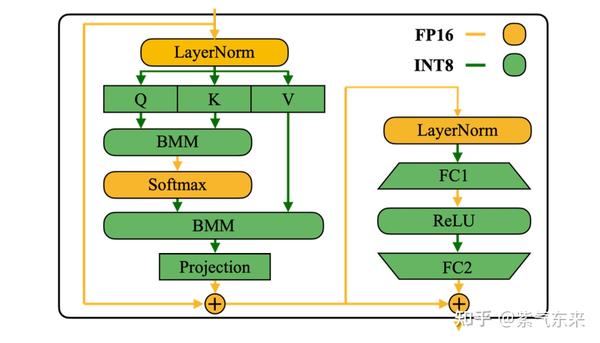
TensorRT-LLM 低精度推理优化:从速度和精度角度的FP8 vs Int8 的全面解析_fp8 int8-CSDN博客
Fast INT8 Inference for Autonomous Vehicles with TensorRT 3 | NVIDIA ...
(PDF) INT8 Winograd Acceleration for Conv1D Equipped ASR Models ...
How to provide calibration data for INT8 quantization with dynamic ONNX ...
Model Quantization for Production-Level Neural Network Inference
Int8 quantization and tvm implementation - Programmer Sought
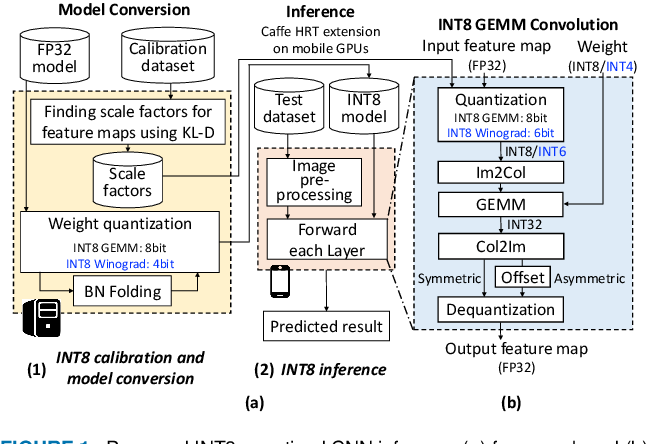
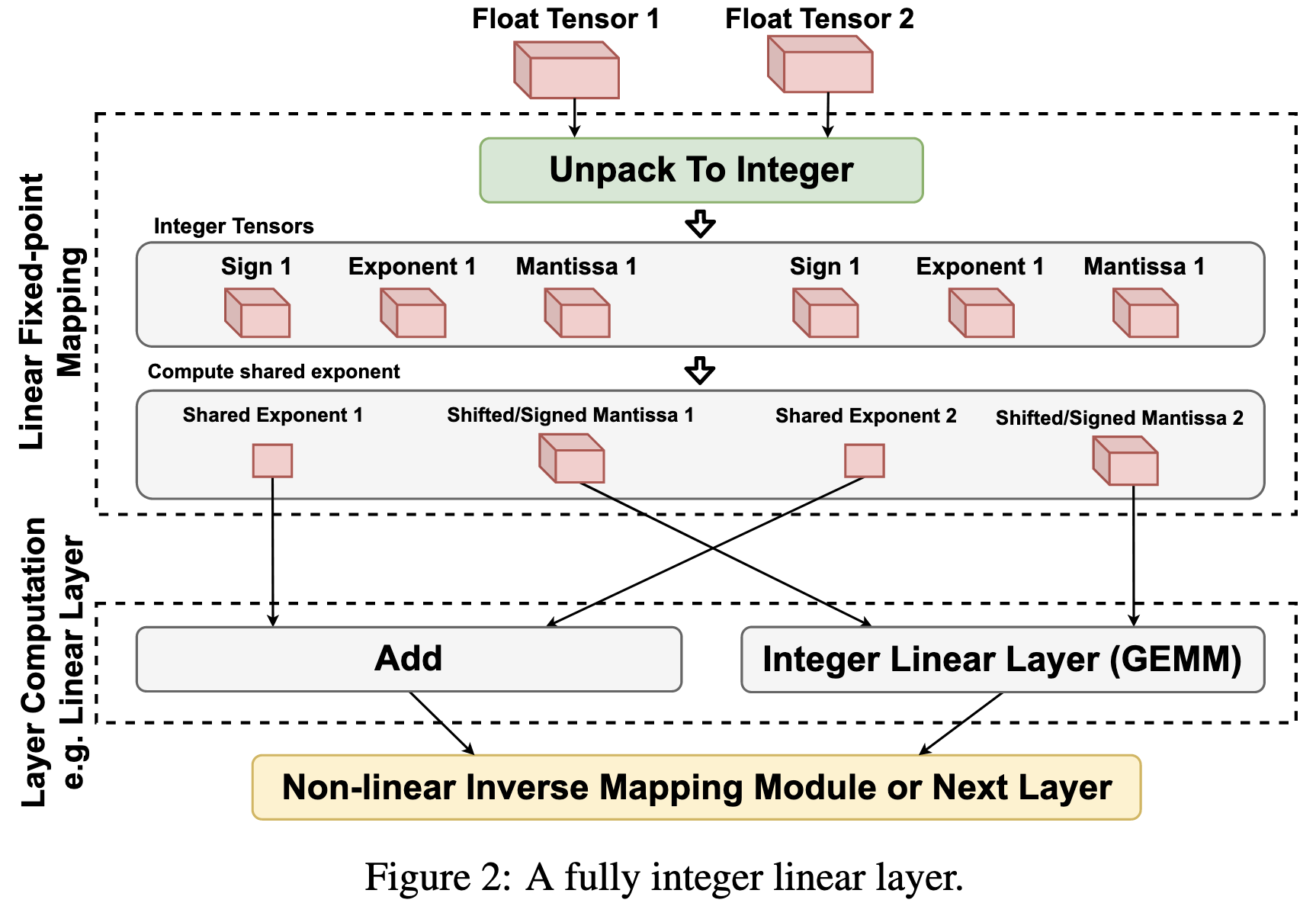
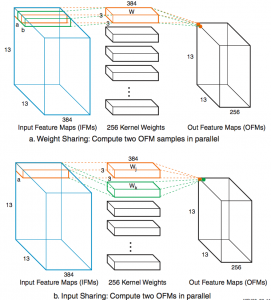
Proposed INT8 quantized CNN inference (a) framework and (b) INT8 GEMM ...
INT8 Quantization — Intel® Extension for TensorFlow* v2.15.0.1 ...
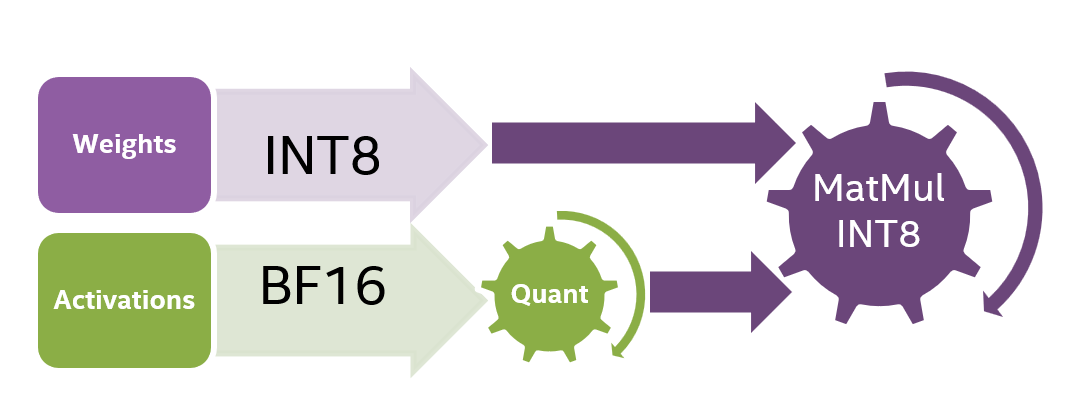
Quantization Methods for 100X Speedup in Large Language Model Inference
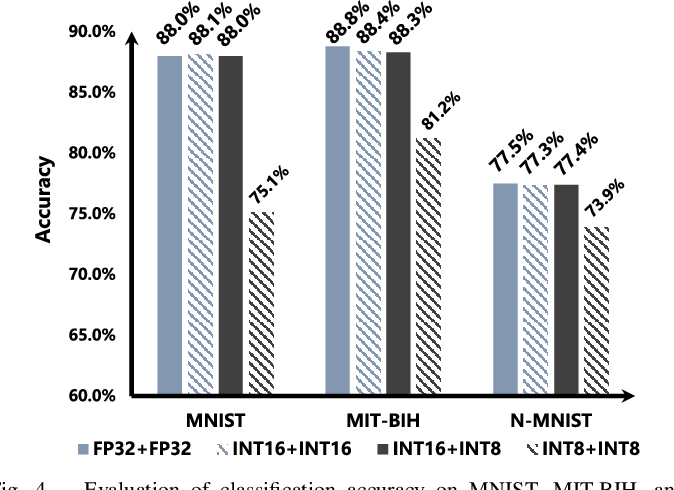
Deep learning INT8 Models from BER threshold to time-threshold with ...
How can I get INT8 weight in my model? · Issue #58 · Xilinx/brevitas ...
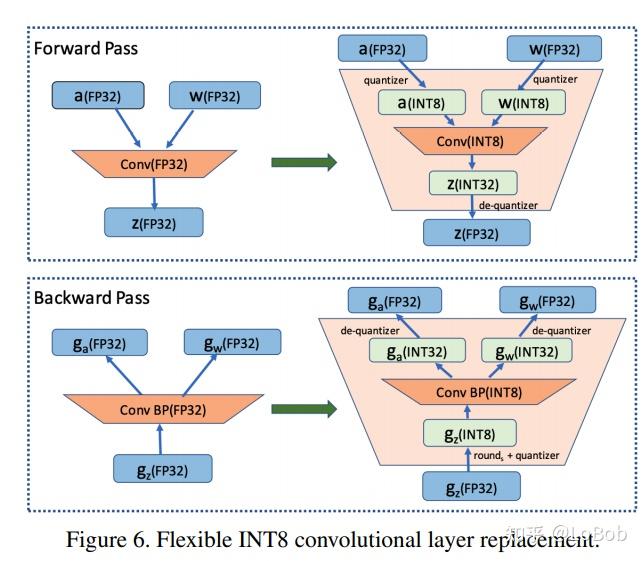
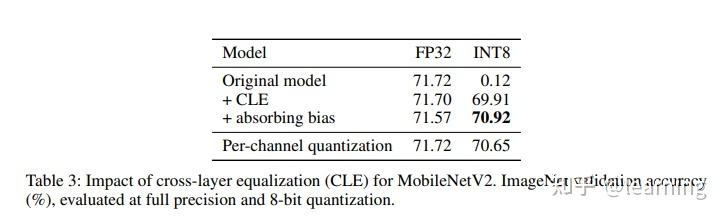
Improving INT8 Accuracy Using Quantization Aware Training and the ...
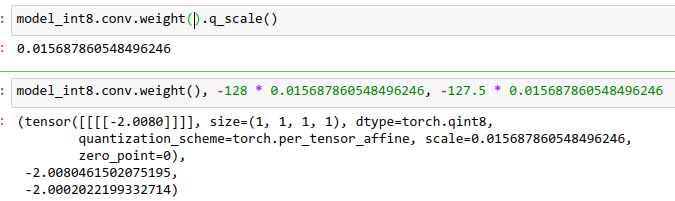
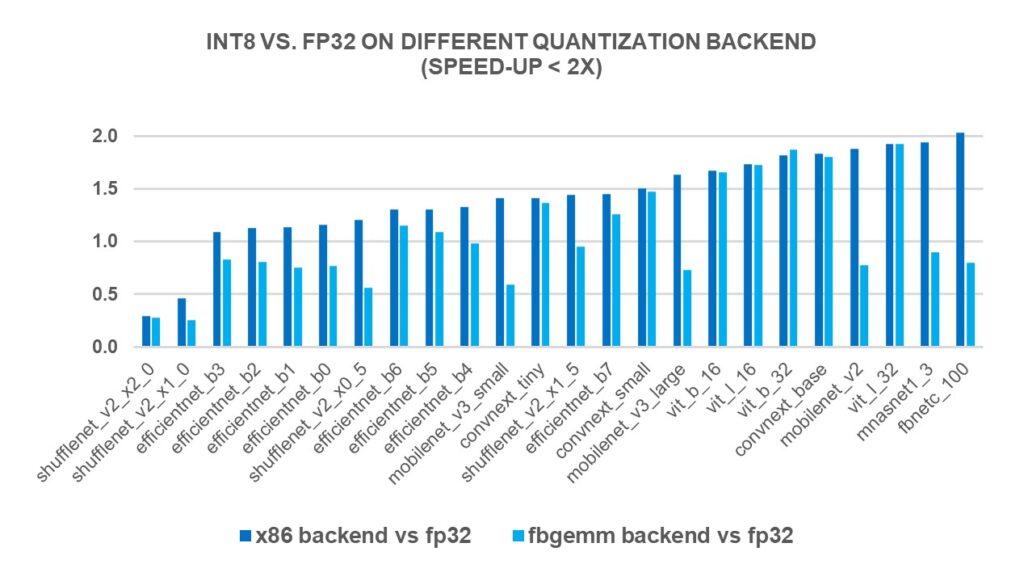
INT8 Quantization for x86 CPU in PyTorch – PyTorch
Popular MCU boards (top) and optimized INT8 models (bottom) used for ...
Can vllm support quantized INT4 and INT8 models? Whether there is a ...
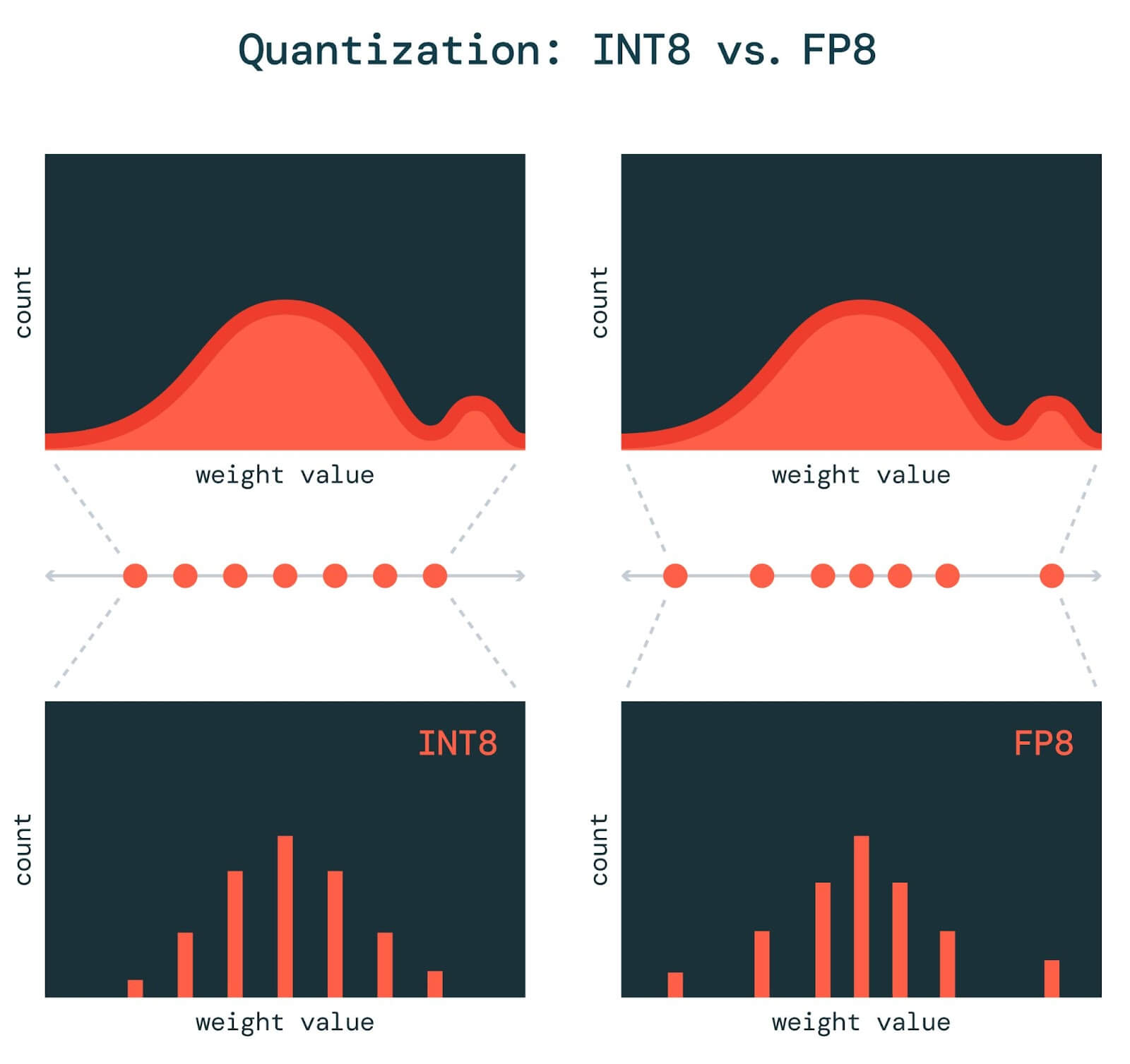
Figure 10 from FP8 versus INT8 for efficient deep learning inference ...
2022-7-24 arXiv roundup: Int8 training at almost no accuracy loss ...
OpenVINO INT8 Quantization for YOLO26 Models: A Hands-On Tutorial | by ...
How to convert yolov8 model to int8, f16 or f32 · Issue #3355 ...
How to persist int8 model? · Issue #921 · mlfoundations/open_clip · GitHub
Deep Learning with INT8 Optimization on Xilinx Devices - Edge AI and ...
How to get a real int8 quanted ONNX model? · Issue #2816 · quic/aimet ...
Deep Learning Int8 Quantization – PCETSK
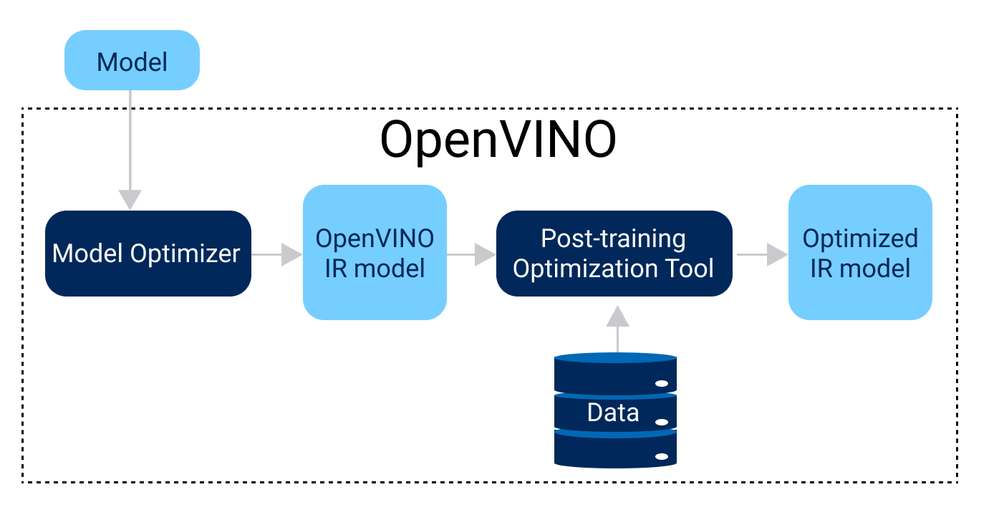
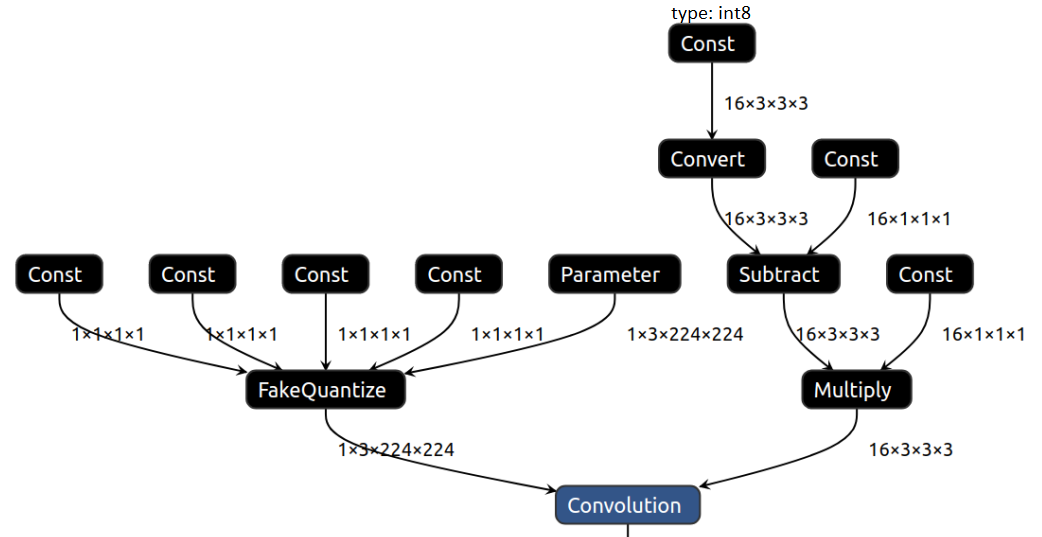
Intermediate Representation Suitable for INT8 Inference — OpenVINO ...
Tips for quantizing AI models to INT8 models for EP-200Q
Inference throughput in showers per seconds for the float32 and int8 ...
NVIDIA GPU的INT8变革:加速大型语言模型推理_CPU_什么值得买
Update #31: Expectations for AI + Healthcare and 8-bit Quantization
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
模型量化(int8)知识梳理 - 知乎
量化 | INT8量化训练 - 知乎
Accelerate StarCoder with 🤗 Optimum Intel on Xeon: Q8/Q4 and ...
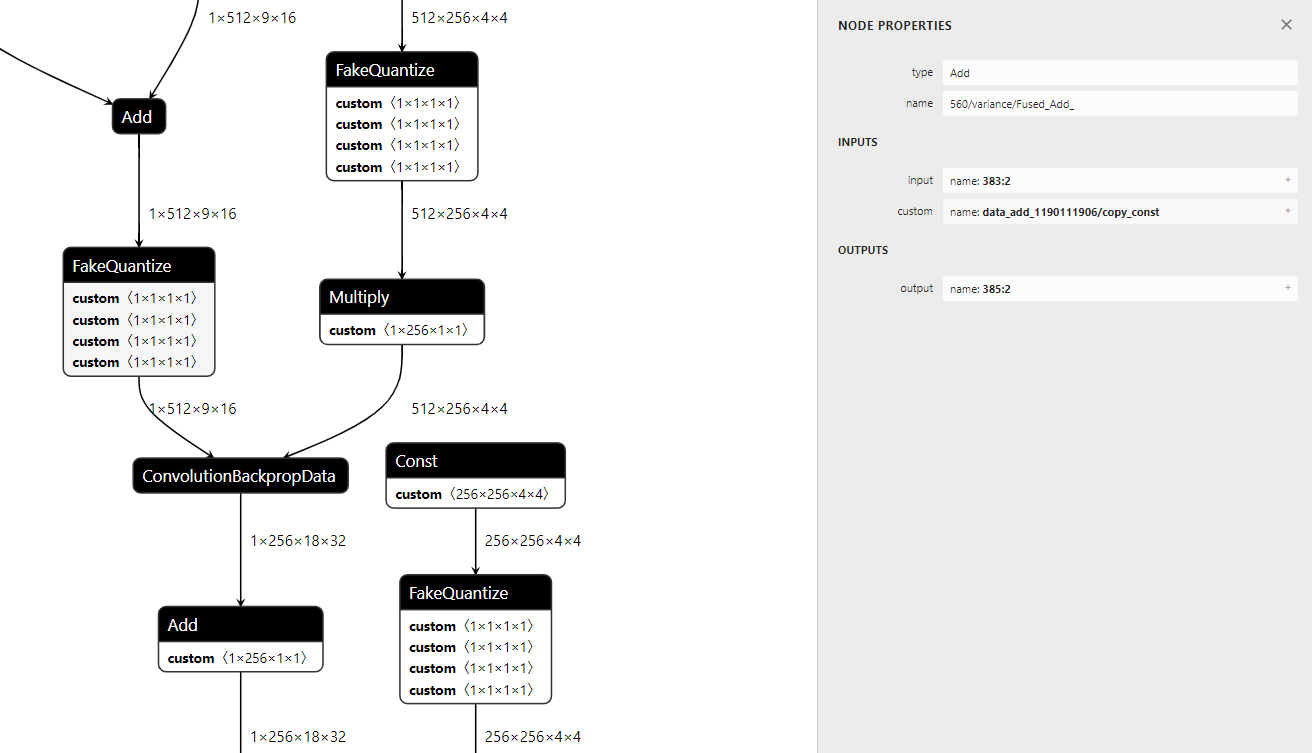
[Bug] Incorrect number of input edges for Add node when load (INT8) IR ...
LLM(十一):大语言模型的模型量化(INT8/INT4)技术 - 知乎
想加速模型推理?试试用int8量化呢_利用transormer 训练的bf16=true的模型,如何用int推理-CSDN博客
DetectNet_v2 - NVIDIA Docs
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
Int8量化-介绍-CSDN博客
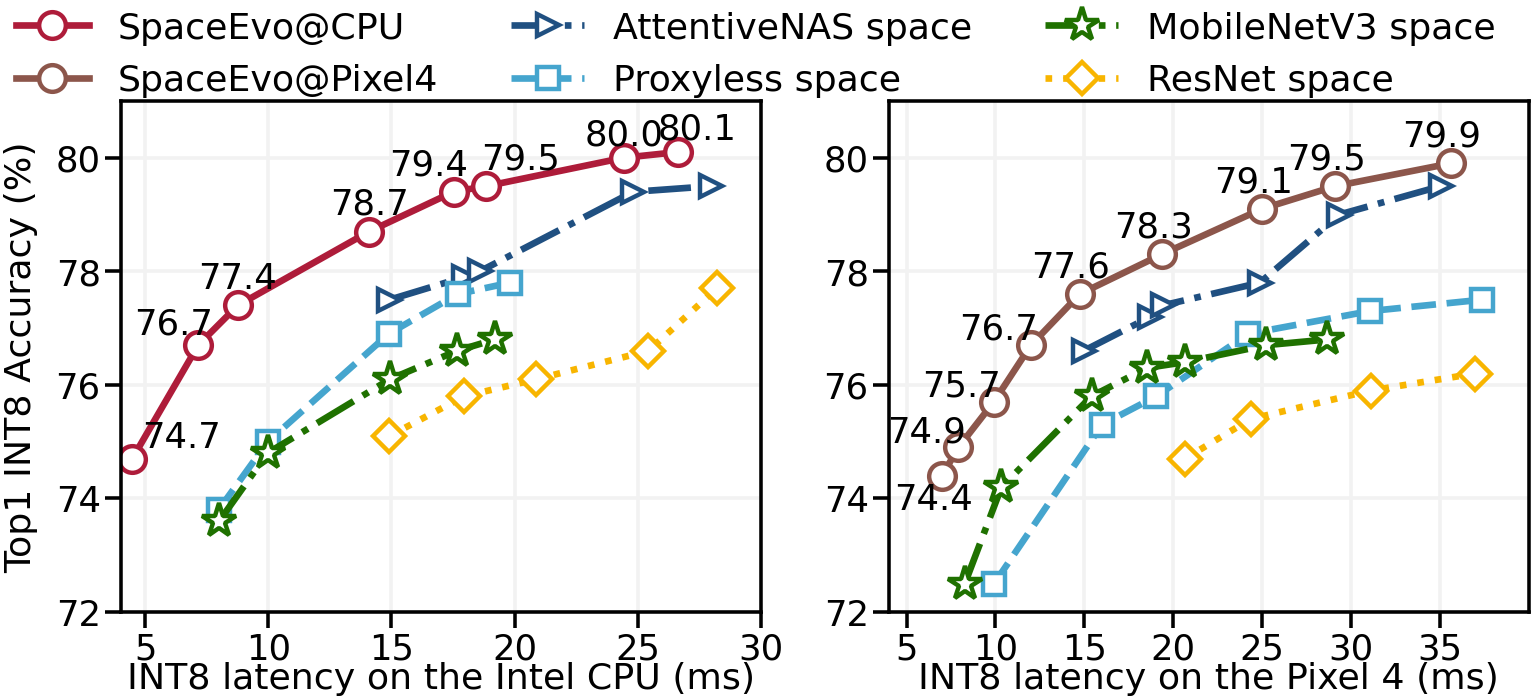
[2303.08308] SpaceEvo: Hardware-Friendly Search Space Design for ...
README.md · Intel/MiniLM-L12-H384-uncased-mrpc-int8-qat-inc at main
GitHub - ThunderFun/ComfyUI-Wan-INT8: Custom node to load Wan in INT8.
int8量化 ssd模型后 load_inference_model加载模型后 exe.run报错 · Issue #18991 ...
(PDF) Understanding INT4 Quantization for Transformer Models: Latency ...
imgailab/sd15-torch-int8 · Hugging Face
How to Install and Run Mediapipe on UNIHIKER
Intel/bart-large-mrpc-int8-dynamic-inc · Hugging Face
PyTorch模型静态量化、保存、加载int8量化模型-腾讯云开发者社区-腾讯云
Overriding torch_dtype=None with `torch_dtype=torch.float16` due to ...
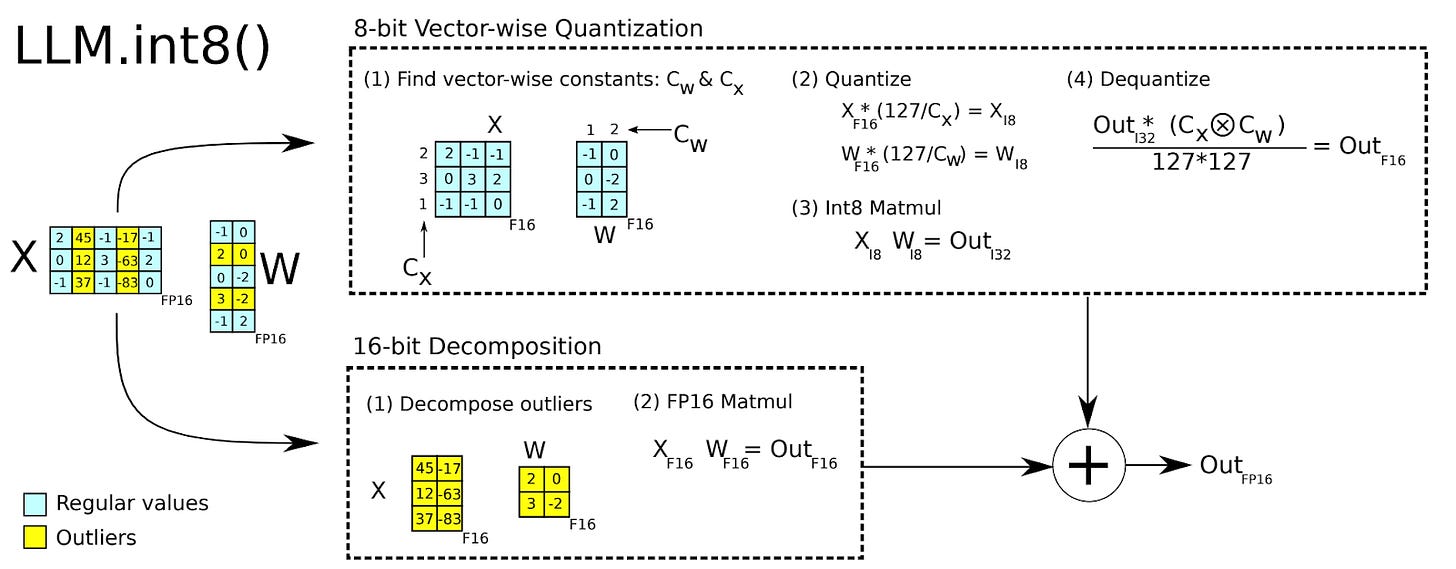
大模型量化之 LLM.int8()方法 - 知乎
Figure 4 from A Low-Power Hybrid-Precision Neuromorphic Processor With ...
When it comes to efficiently serving LLMs, we often hear about ...
iOS 和 swift 中常见的 Int、Int8、Int16、Int32和 Int64介绍「建议收藏」-腾讯云开发者社区-腾讯云
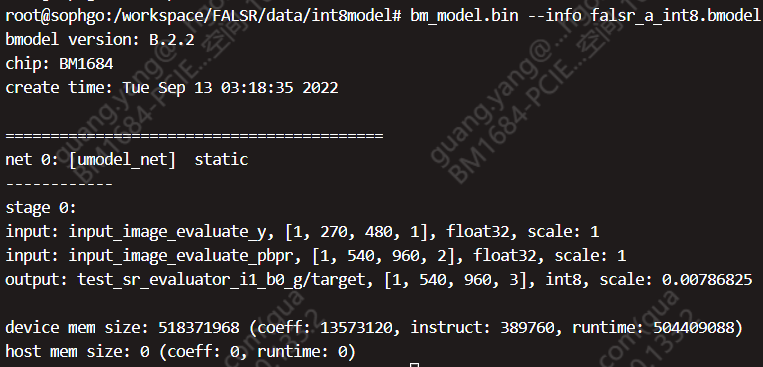
PCIE_FALSR 超分辨率图像模型移植与测试 - 知乎
How to Calculate GPU Requirements for LLM Inference?
Efficient Object Detection with YOLOv8 & OpenVINO on LattePanda Mu
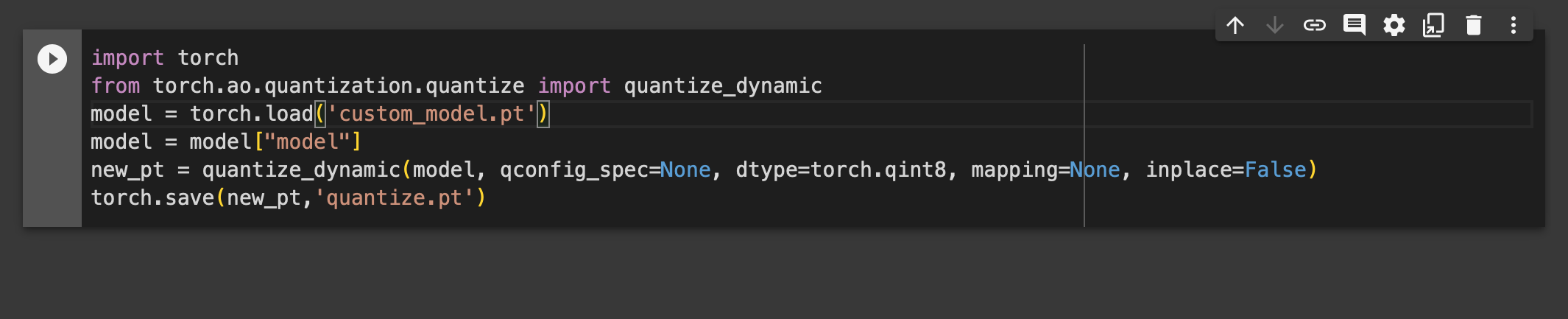
PyTorch模型训练完毕后静态量化、保存、加载int8量化模型_pytorch模型int8量化-CSDN博客
OpenVINO™ Blog | Accelerate Inference of Hugging Face Transformer ...
DetectNet_v2 — Transfer Learning Toolkit 3.0 documentation
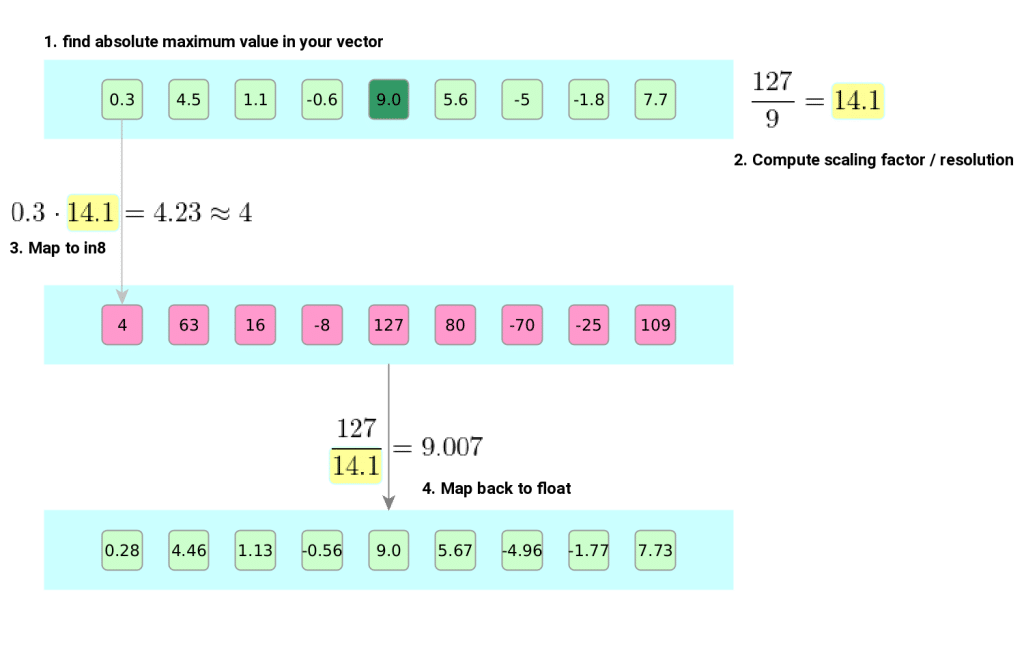
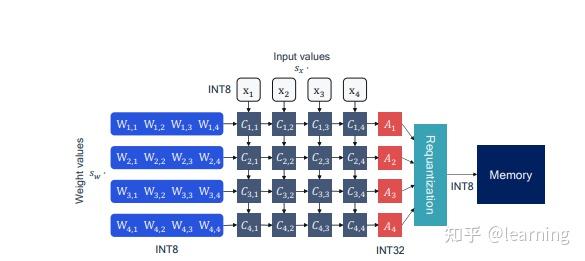
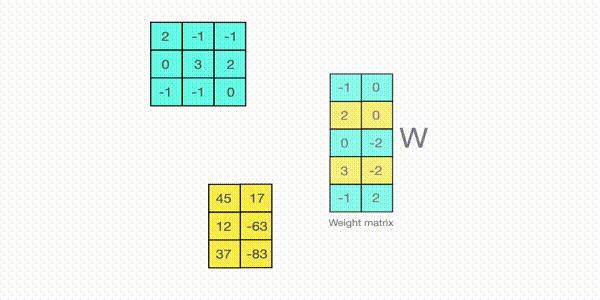
Quantization from FP32 to INT8. | Download Scientific Diagram